
How to fine-tune an LLM using your own data (with OpenAI)
Fine-tuning language models (LLMs) such as those developed by OpenAI allows us to customize these models to better perform specific tasks. This customization is beneficial because while general LLMs are impressively broad in capability, they can often benefit from optimization focused on a particular domain or style of interaction. In this post, we will explore how to fine-tune an LLM using OpenAI's API to create a specialized assistant for data science tasks. All you'll need is your own source of data and an OpenAI API key (more info here: url)
What is Fine-tuning?
Fine-tuning is a process of training a pre-trained model on a new, typically smaller, dataset to specialize its abilities. This process adjusts the weights slightly based on the new data, allowing the model to become more proficient at the desired tasks. It's akin to honing a broad skill into a finely edged craft.
Why Fine-tune?
For data scientists, having an assistant that can understand complex queries and generate Python code can significantly speed up the exploratory and development phases of their projects. By fine-tuning an LLM on a dataset specific to data science queries and code generation, the model becomes much more efficient and accurate at these tasks.
Getting Started
Before you start fine-tuning, you need to set up your environment and prepare your dataset. First, let’s install the necessary libraries:
!pip install --upgrade openai langchainNext, import the required modules:
import openai
from tqdm import tqdm
import jsonSelecting a Base Model
When fine-tuning a model using OpenAI's API, choosing the right base model is crucial. Here's an overview of the available models and some guidance on how to select one that fits your specific needs.
Available Models for Fine-tuning
OpenAI offers a range of models for fine-tuning, each suited to different tasks and capabilities:
- GPT-3.5 Turbo (Recommended Models):
gpt-3.5-turbo-0125: Offers higher accuracy and has been updated to handle requested formats more efficiently.gpt-3.5-turbo-1106: Features improved instruction following and JSON mode support.gpt-3.5-turbo-0613: A stable version suitable for various applications.
- Babbage and Davinci:
babbage-002anddavinci-002: Older models that are still effective for less demanding tasks.
- GPT-4 (Experimental and Specialized Models):
gpt-4-0613: Provides enhanced function calling support.gpt-4-turbo: Incorporates vision capabilities and advanced JSON mode functionality, suitable for the most complex tasks.
Why Choose a Specific Model?
- Task Complexity: GPT-4 models, especially the turbo and vision variants, are designed for complex reasoning and multilingual tasks. They outperform previous models on benchmarks and offer extensive context windows.
- Special Features: Some models have unique features like vision capabilities or enhanced JSON mode, which are critical for specific applications.
- Legacy Compatibility: If your project is built around older API endpoints, models like
gpt-3.5-turbo-instructmight be necessary.
Fine-tuning a Fine-tuned Model
You can also fine-tune a model that has already been fine-tuned. This is particularly useful if you have accumulated additional data and wish to enhance the model without starting from scratch. This iterative fine-tuning can significantly refine the model's performance on your specific tasks.
Conclusion
Choosing the right base model depends largely on your specific needs:
- For general enhancement of response accuracy and format,
gpt-3.5-turbo-0125is typically sufficient. - For the most advanced capabilities, including handling of images and complex data structures, consider
gpt-4-turbo. - If your project requires compatibility with older systems, or if the tasks are less demanding, the older GPT-3.5 models might be appropriate.
Selecting the appropriate model ensures that your fine-tuning efforts are as effective as possible, tailored to both the demands of your tasks and the capabilities you need.
Preparing Your Dataset
For fine-tuning, you require a training set and (optionally) a validation set. OpenAI uses a file format called .jsonl, which looks like this:
{"messages": [{"role": "system", "content": YOUR_SYSTEM_PROMPT_HERE}, {"role": "user", "content": YOUR_EXAMPLE_INPUT_HERE}, {"role": "assistant", "content": YOUR_DESIRED_OUTPUT_HERE}]}
{"messages": [{"role": "system", "content": YOUR_SYSTEM_PROMPT_HERE}, {"role": "user", "content": YOUR_EXAMPLE_INPUT_HERE}, {"role": "assistant", "content": YOUR_DESIRED_OUTPUT_HERE}]}
...These datasets consist of prompts and the expected responses. Here’s how you can prepare these sets:
validation_set = [...]
training_set = [...]
for s in ['validation_set', 'training_set']:
with open(f'{s}.jsonl', 'w') as file:
v = eval(s)
for i in range(len(v)):
item = {
"messages": [
{"role": "system", "content": "You are a data science assistant. Please generate python code to answer the user's prompts."},
{"role": "user", "content": f"Context: {v[i][0]}, Prompt: {v[i][1]}"},
{"role": "assistant", "content": str(v[i][2])}
]
}
json_line = json.dumps(item)
file.write(json_line + '\n')Uploading Data and Fine-tuning
Once your dataset is ready, use the OpenAI API to upload your files and start the fine-tuning process:
client = openai.OpenAI(api_key='YOUR_KEY_HERE')
train_dev = client.files.create(
file=open("training_set.jsonl", "rb"),
purpose="fine-tune"
)
valid = client.files.create(
file=open("validation_set.jsonl", "rb"),
purpose="fine-tune"
)
client.fine_tuning.jobs.create(
training_file=train_dev.id,
validation_file=valid.id,
suffix="gpt_fuego_v1",
model="gpt-3.5-turbo-0125",
hyperparameters={
"n_epochs":2
}
)Check fine-tuning progress
You can look at the fine-tuning progress by going to url and logging in.
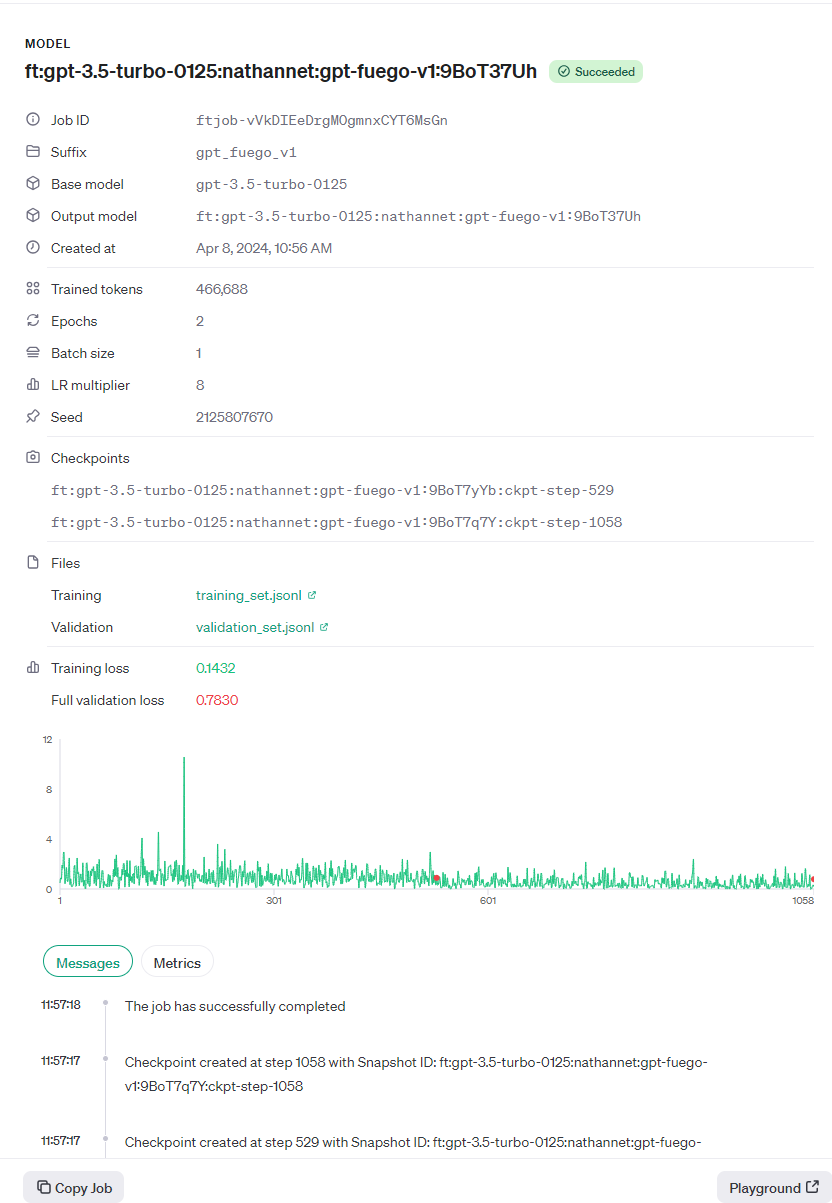
Using Your Fine-tuned Model
After the fine-tuning job is complete, you can use your model to generate responses. Here's how you might set up a function to use your fine-tuned model:
function ret_v(context, prompt) {
response = client.chat.completions.create(
model=MODEL_NAME,
temperature=0.15,
max_tokens=500,
messages=[
{"role": "system", "content": "You are a data science assistant. Please generate python code to answer the user's prompts."},
{"role": "user", "content": "Context: " + context + ", Prompt: " + prompt + " Create a result with only a single line of code using 'df' as an input."}
]
);
return response.choices[0].message.content;
}
// Example usage
output = ret_v("Data showing annual sales", "Calculate the yearly growth rate");
console.log(output);Conclusion
Fine-tuning an LLM for specific tasks like data science can greatly enhance productivity by providing more relevant and accurate responses. By following the steps outlined above, you can create a powerful tool tailored to your needs, accelerating your data science projects significantly.
About the Article Author
